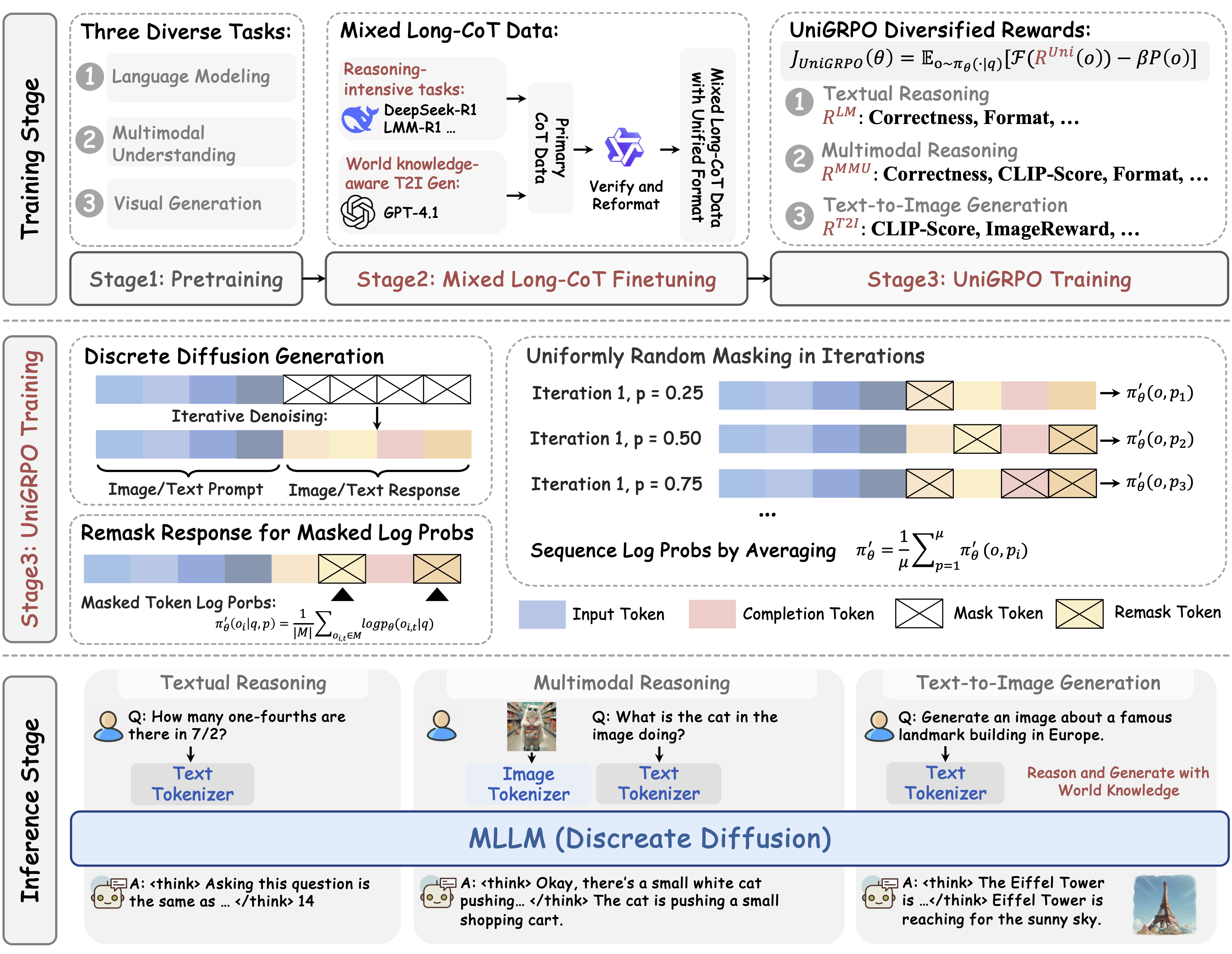
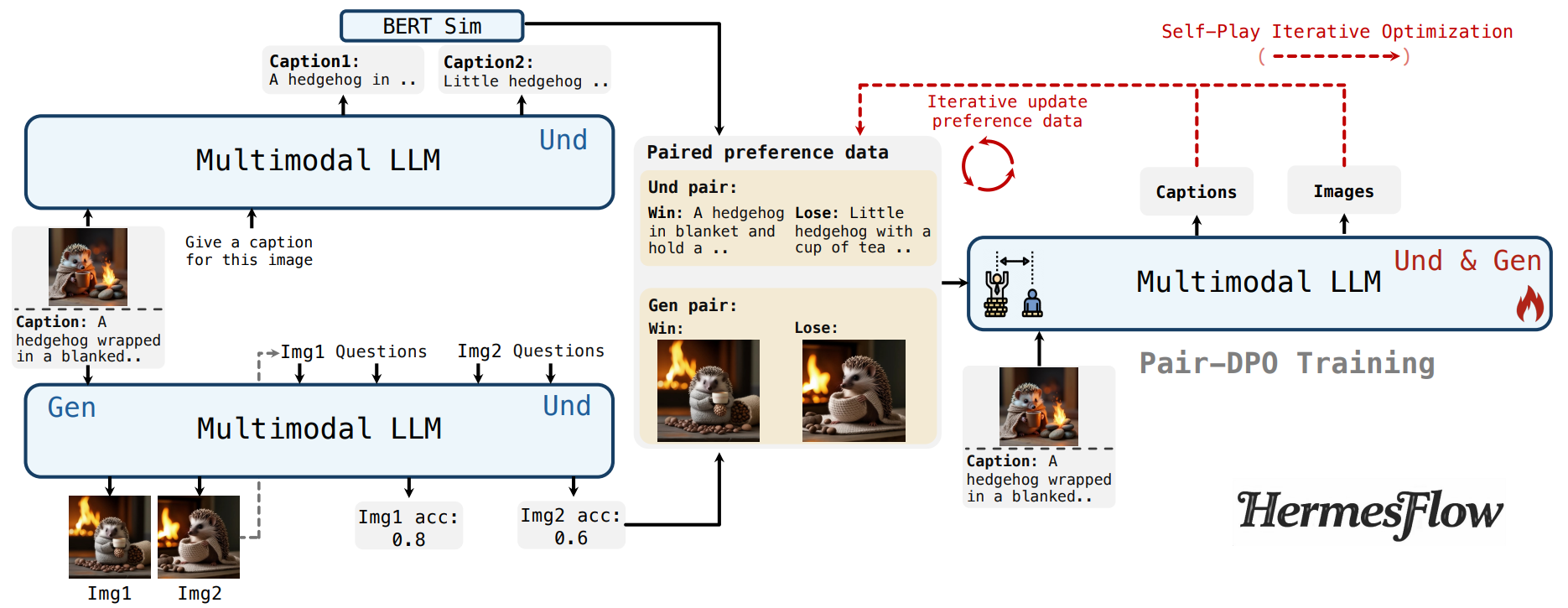
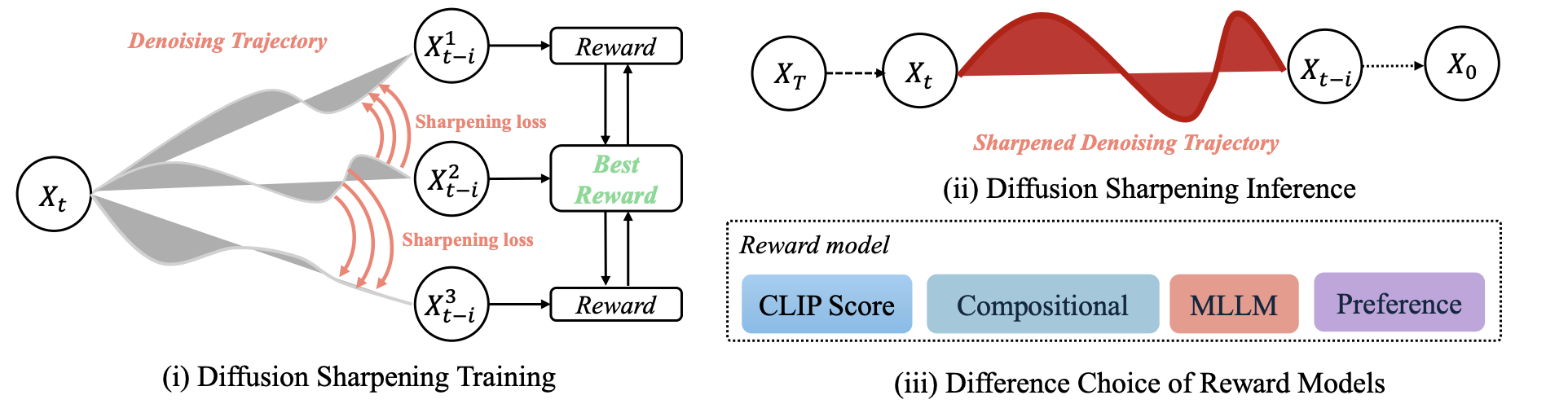
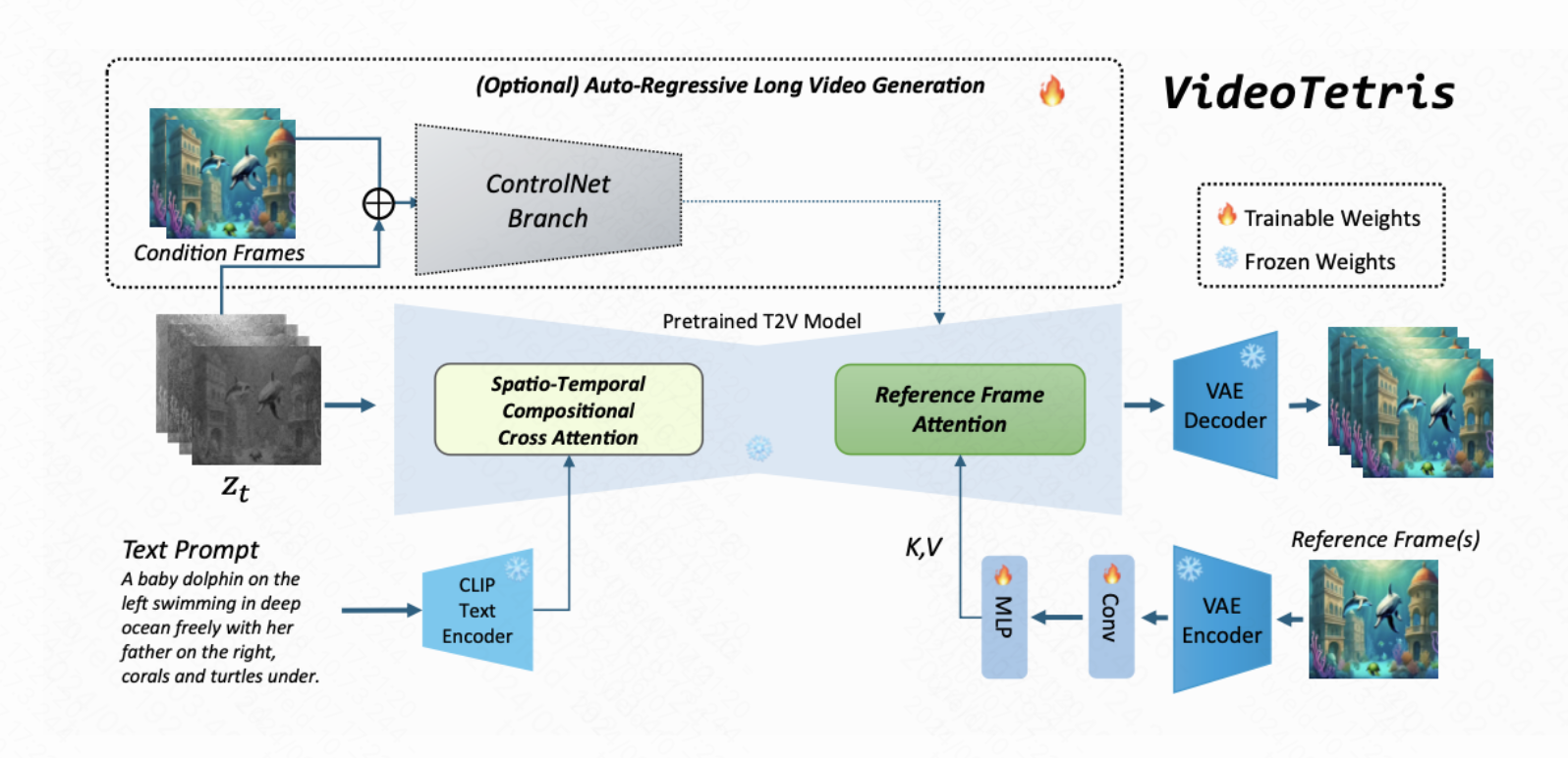
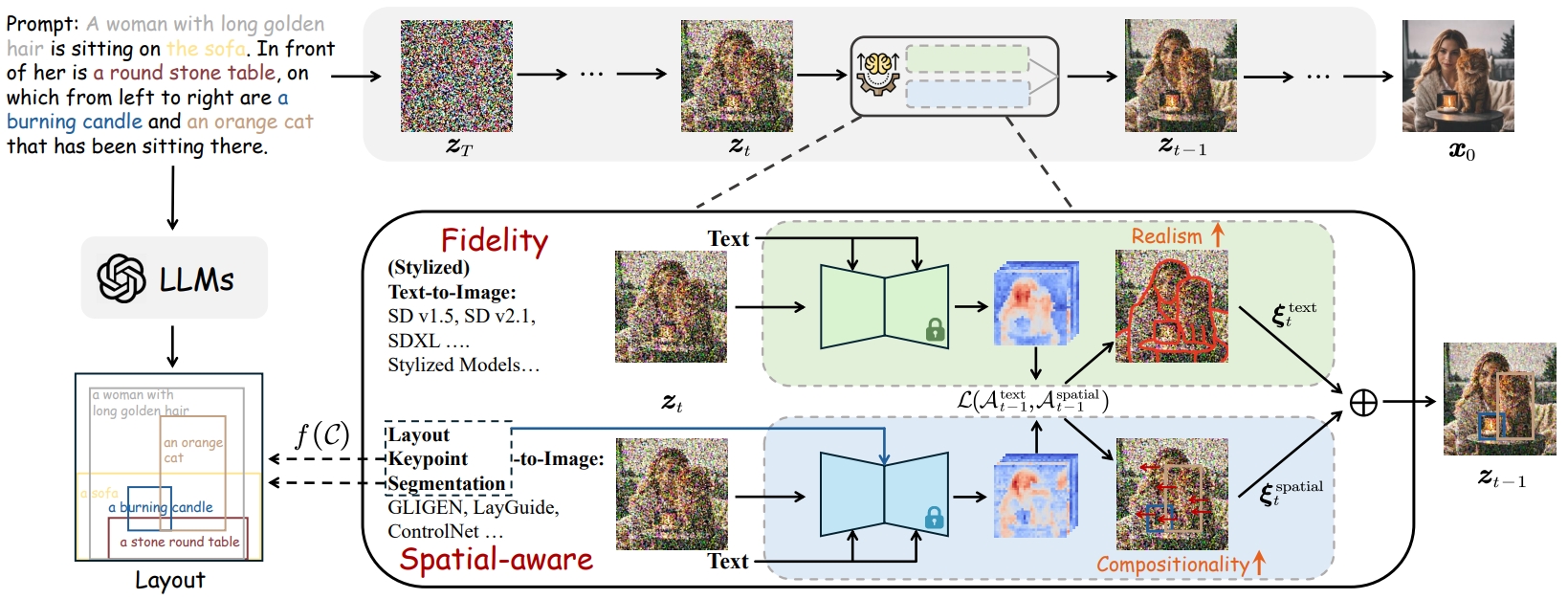
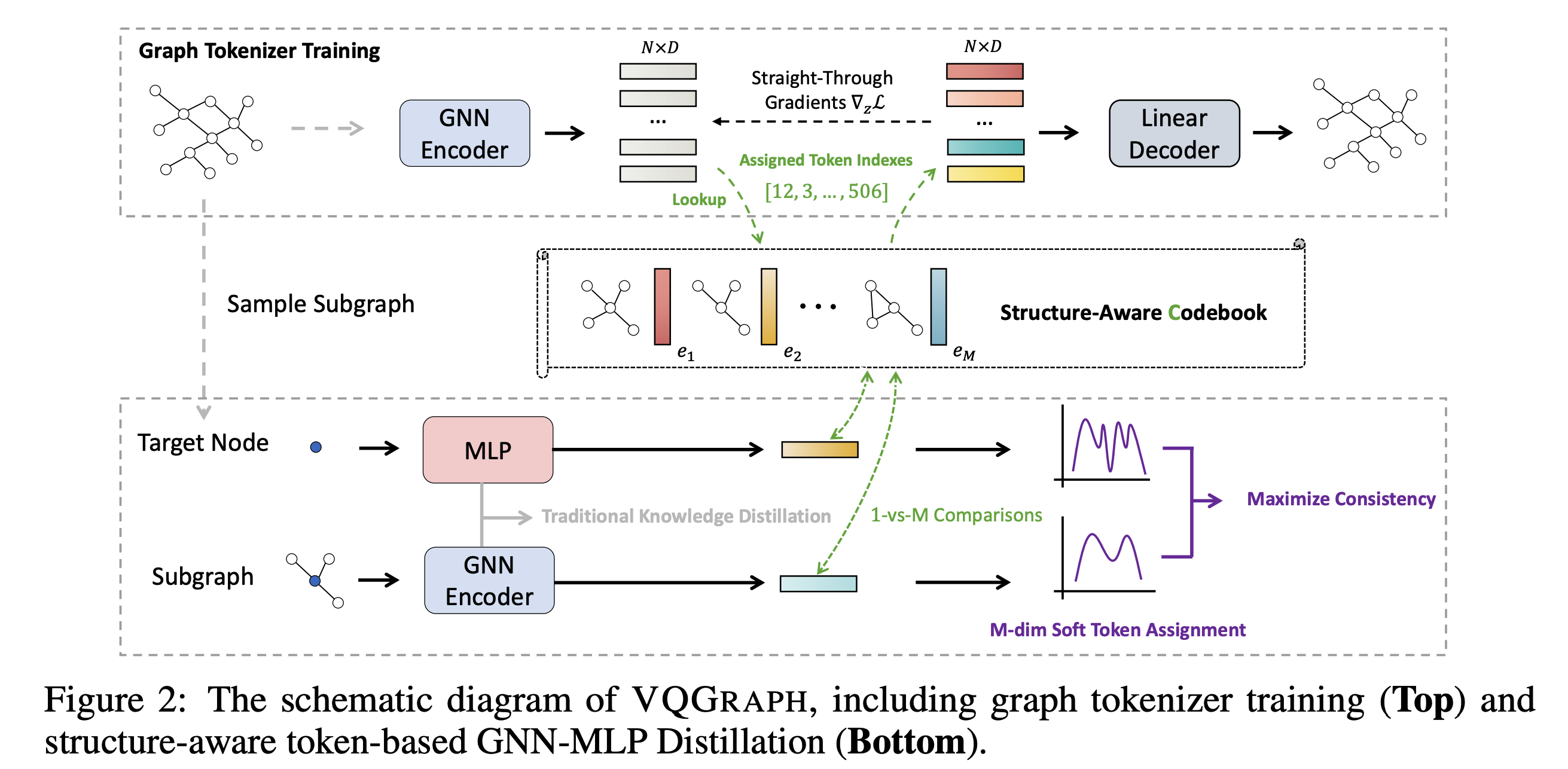
2025 arXiv 2025 MMaDA-Parallel: Multimodal Large Diffusion Language Models for Thinking-Aware Editing and Generation Ye Tian, Ling Yang, Jiongfan Yang, and 10 more authors arXiv preprint arXiv:2511.09611, 2025 arXiv Code NeurIPS 2025 MMaDA: Multimodal Large Diffusion Language Models Ling* Yang, Ye Tian*, Bowen Li, and 4 more authors NeurIPS 2025, 2025 arXiv Code arXiv 2025 HermesFlow: Seamlessly Closing the Gap in Multimodal Understanding and Generation Ling Yang, Xinchen Zhang*, Ye Tian, and 4 more authors arXiv preprint arXiv:2502.12148, 2025 arXiv Code arXiv 2025 Diffusion-Sharpening: Fine-tuning Diffusion Models with Denoising Trajectory Sharpening Ye Tian, Ling Yang, Xinchen Zhang, and 3 more authors arXiv preprint arXiv:2502.12146, 2025 arXiv Code 2024 NeurIPS 2024 Videotetris: Towards compositional text-to-video generation Ye Tian, Ling Yang, Haotian Yang, and 8 more authors Advances in Neural Information Processing Systems, 2024 arXiv Code NeurIPS 2024 Realcompo: Dynamic equilibrium between realism and compositionality improves text-to-image diffusion models Xinchen Zhang, Ling Yang*, Yaqi Cai, and 7 more authors arXiv e-prints, 2024 arXiv Code ICLR 2024 VQGraph: Rethinking Graph Representation Space for Bridging GNNs and MLPs Ling Yang*, Ye Tian*, Minkai Xu, and 7 more authors In The Twelfth International Conference on Learning Representations, 2024 arXiv Code